Data Warehouse vs Data Lake vs Data Lakehouse | What is the Difference ?
Hello everyone, in this article we will discover the difference between Data Warehouse, Data Lake, and Data Lakehouse.
As all you know in today’s world, a business collects all sorts of data from various places. Think about all the informations from sales, customer feedback, web sites logs and events, and even tweets or posts in social media. To make good use of all this data, you need to store it and analyze it properly. That’s where data warehouses, data lakes, and the newer idea of data lakehouses come in. Let’s get into what each of these terms means and why they might matter to you.
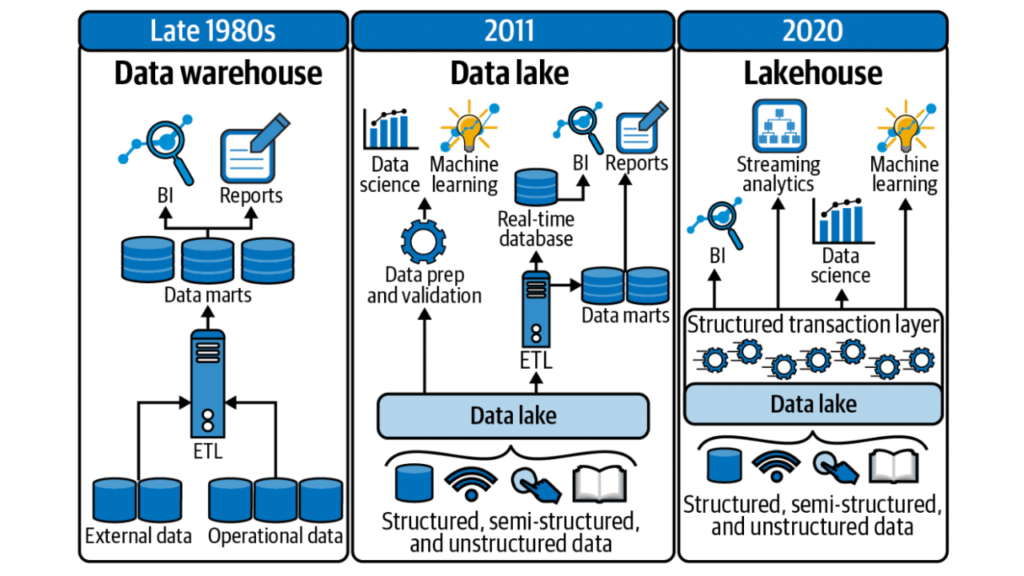
What is a Data Warehouse ?

A data warehouse is a centralized repository where a business can store and manage all its structured, clean, and organized data from various source systems. Unlike data lakes which collect raw data of all types for later use, an data warehourse is optimized for analysis and decision-making, providing high-quality data that’s ready for analytics. It serves as a single source of truth across different business sectors, using Extract, Transform, Load (ETL) tools to ensure the data is useful for business analysts, data scientists, and other users for analytics, machine learning, and reporting.
However, as mentioned before, data warehouses have limitations; they weren’t built to handle unstructured or semi-structured data from sources like social media or sensors, which has led to the advent of data lakes.
Data Lakes: Where All Data Can Swim Freely
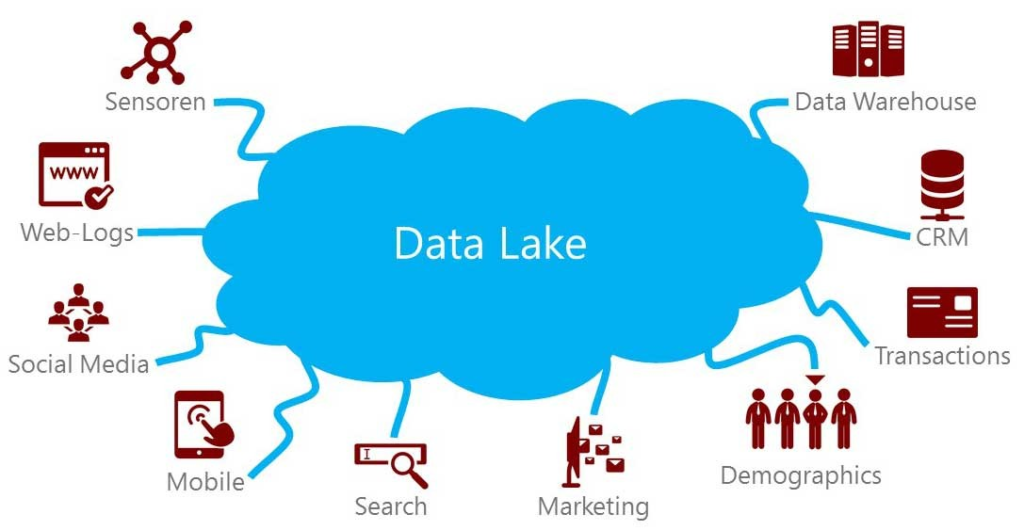
This is where the idea of a “data lake” comes in. Imagine a large pool where you can dump all kinds of data, whether it’s structured nicely, like info in a spreadsheet, or unstructured, like a bunch of photos. You can just pile it in there and figure out later how you might use it.
The advantage here is obvious: you can store tons of data without having to organize it first, which can save time and let you handle a lot more different types of info. But be careful—without careful management, your data lake can turn into a mess where it’s hard to find anything useful, a bit like a junk drawer in your kitchen.
Data Lakehouses: The Best of Both Worlds?
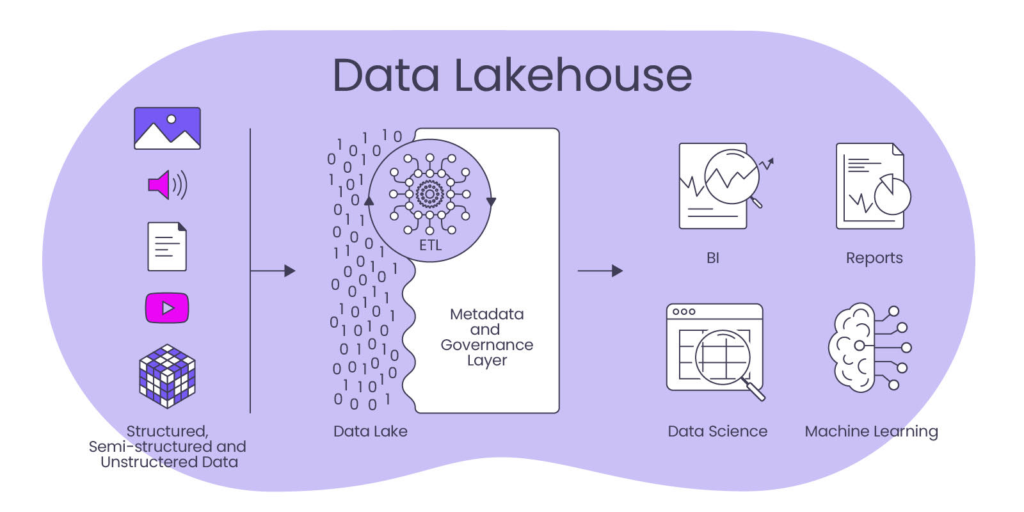
What is a Data Warehouse ?
Data lakehouses aim to merge the benefits of data warehouses and data lakes. They accommodate both batch (periodically collected) and real-time data streams. Whether it’s structured content suitable for a data warehouse or unstructured data for a data lake, a data lakehouse integrates these sources seamlessly. A shared data catalog sits at the heart of this architecture, where users can easily discover required datasets and apply SQL-based ETL operations on-demand, leveraging big data processing tools like Apache Spark.
While data lakehouses bring the best of both worlds, they also inherit challenges in data governance and metadata management, given the combination of structured and unstructured ecosystems. Nevertheless, platforms like Microsoft Azure, AWS, and Google Cloud are optimizing the creation of data lakehouses, though the concept is still evolving.
Why Should You Care?
Whether you’re in charge of a business or trying to understand how today’s companies use data, knowing the difference between these terms is useful because it tells you a lot about how a business can use all the info it collects.
A good system for storing and analyzing data means a company can understand its customers better, make smarter choices, and even predict what will happen next in their market. As businesses and technology grow, we might be hearing more about these data lakehouses as a way to keep everything in check.
You can find another article about the difference between a database, a data warehouse, and a data lake here.
