Hello everyone, in this article, we will explore the fundamental distinctions between Supervised and Unsupervised Learning.
Machine Learning (ML) stands as one of the most revolutionary technologies in the computing world today, with its ability to learn from data and improve over time. It’s no wonder businesses and researchers are eager to leverage ML to glean insights and make predictions. At the heart of ML are two central strategies known as supervised and unsupervised learning. Each of these learning modes plays a critical role in how ML models interpret and process data.
Supervised Learning: Guidance Leads to Precision
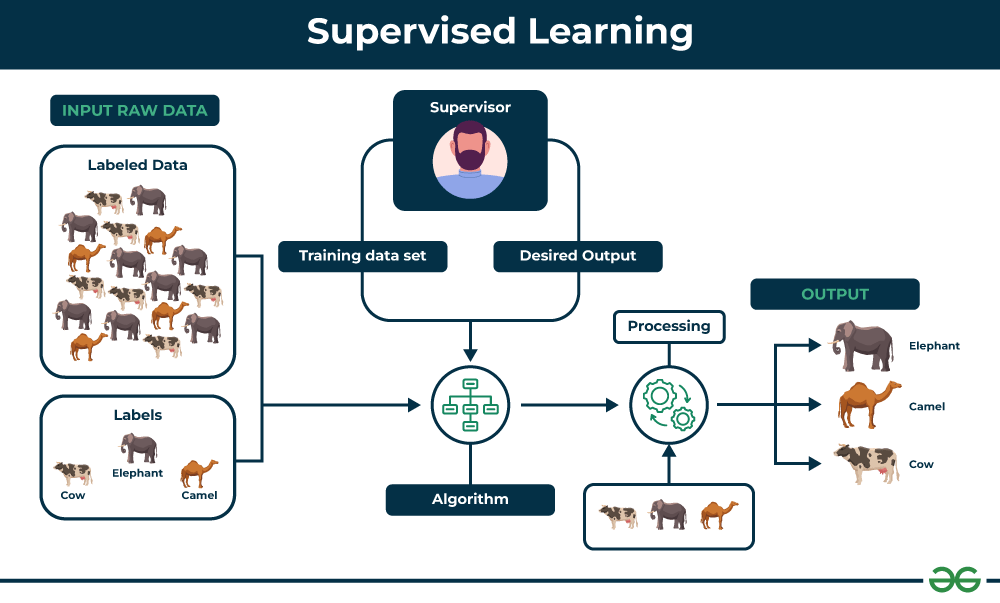
Supervised learning operates on a foundation built upon labeled data. Simply put, this learning process works with datasets that have inputs paired with the correct outputs. This enables the algorithm to learn by example. As it gets fed with more labeled data, it begins to identify patterns and understand the relationships between the input and output. Over time, this allows the algorithm to make accurate predictions or categorizations on new, unseen data.
The effectiveness of supervised learning can be seen in two main tasks: classification and regression. Classification algorithms, such as decision trees and support vector machines, categorize data into discrete labels—think ‘spam’ or ‘not spam’. Conversely, regression algorithms like linear and logistic regression predict a continuous outcome, such as house prices or stock values.
Unsupervised Learning: Self-Learning through Discovery

Unsupervised learning differs fundamentally as it deals with data that isn’t labeled. There’s no guide for the algorithm, no correct answers provided. Instead, the algorithm must comb through data, searching for patterns and structures on its own. These patterns can then be used to group the data in meaningful ways. The unsupervised learning approach is indispensable for tasks such as clustering, association, and dimensionality reduction.
Imagine a business trying to understand its customer base; clustering can identify groups of customers with similar purchasing behaviors, while association rules can reveal which products are frequently bought together. Dimensionality reduction can simplify data without losing valuable information, useful when making datasets more manageable or when removing noise from data, such as cleaning up image quality.
The Differences Between Supervised and Unsupervised Learning
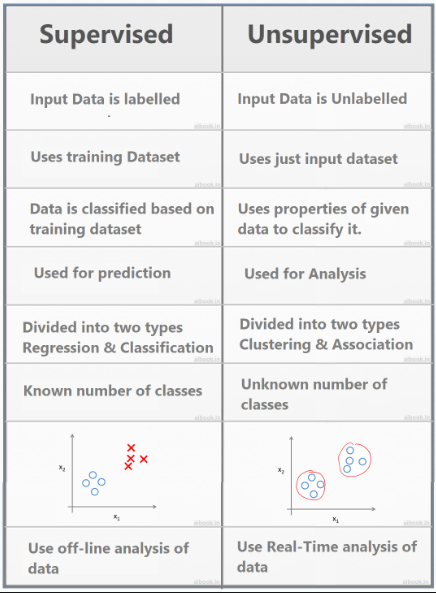
The core distinction lies in their approach to learning from data. Supervised learning algorithms adjust their parameters based on feedback from the comparison of their predictions against the known outputs. This typically makes supervised models more accurate but reliant on human-labeled data. Unsupervised learning algorithms, however, are free to interpret the data’s inherent structure without pre-labeled correct answers, making them suitable for finding hidden patterns in the data but generally less precise in predicting outcomes.
Which Learning Method to Choose?
Your choice depends on the data you have and the objectives you seek. Supervised learning often takes the lead due to its accuracy and efficiency. It’s particularly useful when the intended outcome is clear and labeled data is available. However, unsupervised learning holds significant value, especially when dealing with unlabeled data or when the goal is to explore the data for unknown patterns.
Sometimes, the middle ground—semi-supervised learning—combines elements of both. This approach uses limited labeled data alongside a larger pool of unlabeled data. This can be especially beneficial in fields like medical imaging, where labeled examples can be scarce and valuable.
